캐시란?
웹뷰를 사용하다 보면 캐시라는 말을 자주 듣는다. 프론트엔드 개발자가 존재한다면 캐시라는 키워드를 더 자주 들을 수 있다. 그런데 도대체 캐시란 게 뭘까?
캐시라는 개념은 안드로이드에서도 사용되기는 하지만, 정확히 캐시가 무엇이고 왜 필요한지는 모르는 상태라서 공부하기 위해 포스팅한다. 캐시 그거잖아 그거 돈
캐시의 사전적 정의는 아래와 같다.
고속 기억 장치, (무기 등의) 은닉처
사전적 정의로만 보면 더 모르겠으니 위키백과를 확인해 본다.
https://en.wikipedia.org/wiki/Cache_(computing)
Cache (computing) - Wikipedia
From Wikipedia, the free encyclopedia Additional storage that enables faster access to main storage Diagram of a CPU memory cache operation In computing, a cache ( KASH)[1] is a hardware or software component that stores data so that future requests for th
en.wikipedia.org
캐시는 해당 데이터에 대한 향후 요청이 더 빠르게 처리될 수 있도록 데이터를 저장하는 하드웨어 or 소프트웨어 구성요소다. 캐시에 저장된 데이터는 이전 계산의 결과일 수 있고, 다른 곳에 저장된 데이터의 복사본일 수 있다. 요청한 데이터를 캐시에서 찾을 수 있으면 캐시 적중(cache hit)이 발생하고, 찾을 수 없다면 캐시 미스가 발생한다. 캐시 적중은 캐시에서 데이터를 읽어 제공된다. 이는 결과를 다시 계산하거나 느린 데이터 저장소에서 읽는 것보다 빠르다
따라서 캐시에서 처리 가능한 요청이 많을수록 시스템 성능은 더 빨라진다. 비용 효율성을 높이고 데이터를 효율적으로 사용하려면 캐시가 상대적으로 작아야 한다...(중략)...캐시를 쓰면 여러 미세한 전송을 더 크고 효율적인 요청으로 조합해서 기본 리소스의 처리량을 높일 수 있다
하드웨어는 다시 쓰일 가능성이 있는 데이터를 임시 저장하기 위한 메모리 블록으로 캐시를 구현한다. CPU, SSD, HDD에는 하드웨어 기반 캐시가 포함되는 경우가 많지만 웹 브라우저와 웹 서비스는 일반적으로 소프트웨어 캐싱에 의존한다. 캐시는 항목 풀(pool of entries)로 구성된다. 각 항목(entry)에는 일부 백업 저장소의 동일한 데이터의 복사본인 관련 데이터가 있다. 각 항목에는 해당 항목이 복사본인 백업 저장소에 있는 데이터의 ID를 저장하는 태그도 있다
캐시 클라이언트(CPU, 웹 브라우저, OS)는 백업 저장소에 존재한다고 추정되는 데이터에 접근해야 하는 경우 먼저 캐시를 확인한다. 원하는 데이터와 일치하는 태그가 있는 항목을 찾을 수 있으면 항목의 데이터가 대신 쓰인다. 이것을 캐시 적중이라고 한다. 웹 브라우저 프로그램은 디스크의 로컬 캐시를 검사해서 특정 URL에 있는 웹 페이지 컨텐츠의 로컬 복사본이 있는지 확인할 수 있다. 캐시 적중으로 이어지는 접근 비율을 캐시 적중률이라고 한다. 반대로 캐시를 검사한 결과 원하는 태그가 포함된 항목이 없는 경우를 캐시 미스라고 한다
요청된 데이터가 검색되면 일반적으로 다음 접근을 위해 캐시에 복사된다...(중략)...교체할 항목을 선택하는 데 쓰이는 경험적 방법을 교체 정책이라 한다. 널리 쓰이는 대체 정책 중 하나인 최근에 사용된 항목(LRU)은 가장 오래된 항목, 즉 다른 항목보다 최근에 액세스된 항목을 대체한다...(중략)
< 소프트웨어 캐시 >
- 웹 캐시 : 웹 브라우저와 프록시 서버는 웹 캐시를 써서 웹 페이지 및 이미지 같은 서버의 이전 응답을 저장한다. 웹 캐시는 이전에 캐시에 저장된 정보를 재사용할 수 있기 때문에 네트워크를 통해 전송해야 하는 정보량을 줄인다. 이는 웹 서버의 대역폭과 처리 요구사항을 줄이고, 웹 사용자의 응답성을 향상시키는 데 도움이 된다. 웹 브라우저는 내장된 웹 캐시를 쓰지만, 일부 인터넷 서비스 제공업체(ISP) 또는 조직에선 해당 네트워크의 모든 사용자가 공유하는 웹 캐시인 캐싱 프록시 서버도 사용한다...(중략)
즉 캐시란 자주 사용하는 데이터를 미리 복사해 두는 임시 저장소를 가리키는 말이다. 복사해 두는 이유는 다시 해당 페이지에 접근할 경우, 처음부터 다시 읽어오는 것보다 캐시에 저장된 데이터들을 활용하면 빠르게 불러올 수 있고, 이 결과로 사용자 경험도 좋아진다.
극단적 예시로 블로그, 유튜브, 네이버 등의 포털 사이트를 처음 열면 1시간이 걸린다고 가정한다. 만약 캐시가 없을 경우 봤던 사이트를 나온 후 다시 접근하면 어떻게 될까? 저장된 데이터가 없으니 브라우저는 서버에 요청해서 다시 데이터를 요청하고, 그리는 작업을 또 1시간동안 진행한다. 이는 새로고침해도 마찬가지다.
하지만 캐시가 있다면 이야기는 다르다. 로고 이미지, 블로그의 배경 이미지, 카테고리 같은 상대적으로 덜 바뀌는 요소들은 저장해두고, 게시글 목록 같이 자주 바뀌는 요소들만 새로 요청해서 가져온다면 좀 더 빠르게 사용자에게 화면을 보여줄 수 있을 것이다.
하지만 "임시" 저장소라는 점에 주목해야 한다. 캐시는 영속적인 데이터가 아니다. 또한 LRU 캐시가 그러하듯 오래된 캐시는 새로운 캐시에 의해 제거될 수 있음에 주의해야 한다.
다른 사람들은 어떻게 설명하는지 확인한다.
https://mangkyu.tistory.com/69
[Server] Cache(캐시)란?
1. 캐시(Cache)란? [ Cache ] Cache란 자주 사용하는 데이터나 값을 미리 복사해 놓는 임시 장소를 가리킨다. 아래와 같은 저장공간 계층 구조에서 확인할 수 있듯이, 캐시는 저장 공간이 작고 비용이
mangkyu.tistory.com
캐시란 자주 쓰는 데이터, 값을 미리 복사해 놓는 임시 장소를 가리킨다. 아래와 같은 저장공간 계층 구조에서 확인할 수 있듯이 캐시는 저장 공간이 작고 비용이 비싼 대신 빠른 성능을 제공한다

캐시는 아래와 같은 경우에 사용을 고려하면 좋다
1. 원래 데이터에 접근하는 시간이 오래 걸릴 경우(서버의 균일한 API 데이터)
2. 반복적으로 동일한 결과를 돌려주는 경우(이미지, 썸네일 등)
캐시에 데이터를 미리 복사해 두면 계산이나 접근 시간 없이 더 빠르게 데이터에 접근 가능하다. 결국 캐시란 반복적으로 데이터를 불러오는 경우, 지속적으로 DBMS 또는 서버에 요청하는 게 아니라 메모리에 저장했다가 불러다 쓰는 걸 의미한다. 엔터프라이즈급 앱에서는 DBMS의 부하를 줄이고 성능을 높이기 위해 캐시를 사용한다
아래 그래프는 Long Tail 법칙의 그래프다
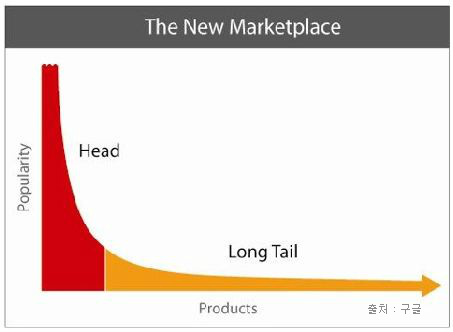
Long Tail 법칙은 20%의 요구가 시스템 리소스 대부분을 사용한다는 법칙이다. 때문에 20%의 기능에 캐시를 사용함으로써 리소스 사용량은 대폭 줄이고 성능은 대폭 향상시킬 수 있다
https://www.techtarget.com/searchstorage/definition/cache
What is Cache (Computing)?
Learn about the various types of caches, how they work, how they're used and the benefits -- like improved performance -- as well as the drawbacks of them.
www.techtarget.com
캐시는 컴퓨팅 환경에서 뭔가(일반적으로 데이터)를 일시적으로 저장하는 데 쓰이는 하드웨어 또는 소프트웨어다. 최근에 또는 자주 접근하는 데이터의 성능을 향상시키는 데 쓰이는 더 빠르고 비용이 비싼 소량의 메모리다. 캐시된 데이터는 주 저장소와 별도로 접근 가능한 저장 매체에 임시 저장된다. 캐시는 일반적으로 CPU, 앱, 웹 브라우저 및 OS에서 사용된다. 캐시는 대량 또는 주 저장소가 클라이언트의 요구를 따라갈 수 없기 때문에 사용된다. 캐시는 데이터 접근 시간을 줄이고 대기 시간을 줄이며 I/O를 향상시킨다. 거의 모든 애플리케이션 워크로드가 I/O 작업에 의존하기 때문에 캐싱 프로세스는 애플리케이션 성능을 향상시킨다