OCR(광학 문자 인식)이란?
바코드를 OCR로 인식한다고 흔히 말한다. 이 때 OCR이란 단어는 무엇일까? 위키백과에선 아래와 같이 설명한다.
https://ko.wikipedia.org/wiki/%EA%B4%91%ED%95%99_%EB%AC%B8%EC%9E%90_%EC%9D%B8%EC%8B%9D
광학 문자 인식 - 위키백과, 우리 모두의 백과사전
위키백과, 우리 모두의 백과사전. 포터블 스캐너로 실시간 광학 문자 인식(OCR) 과정을 보여주는 동영상. 광학 문자 인식(Optical character recognition; OCR)은 사람이 쓰거나 기계로 인쇄한 문자의 영상
ko.wikipedia.org
OCR은 사람이 쓰거나 기계로 인쇄한 문자의 영상을 이미지 스캐너로 얻어서 기계가 읽을 수 있는 문자로 변환하는 것이다. 이미지 스캔으로 얻을 수 있는 문서의 활자 영상을 컴퓨터가 편집 가능한 문자코드 등의 형식으로 변환하는 소프트웨어로써 일반적으로 OCR이라 하며 OCR은 인공지능이나 기계 시각의 연구분야로 시작됐다.
초기 시스템은 특정 서체를 읽기 위해 미리 해당 서체의 샘플을 읽는 걸 뜻하는 트레이닝이 필요했지만 지금은 대부분의 서체를 높은 확률로 변환 가능하다. 몇몇 시스템에선 읽어들인 이미지에서 그것과 거의 일치하는 워드 프로세서 파일과 같은 문서 포맷으로 된 출력 파일을 생성할 수 있으며 그 중에는 이미지처럼 문서 이외의 부분이 포함돼 있어도 제대로 인식하는 것도 있다
https://en.wikipedia.org/wiki/Optical_character_recognition
Optical character recognition - Wikipedia
From Wikipedia, the free encyclopedia Computer recognition of visual text Video of the process of scanning and real-time optical character recognition (OCR) with a portable scanner Optical character recognition or optical character reader (OCR) is the elec
en.wikipedia.org
OCR은 스캔한 문서, 문서 사진, 장면 사진, 이미지에 중첩된 자막 텍스트 등 인쇄된 종이 데이터 기록의 데이터 입력 형식으로 널리 쓰이며 인쇄된 텍스트를 디지털화하는 일반적인 방법이다. OCR은 패턴 인식, 인공지능, 컴퓨터 비전을 연구하는 분야다. 초기 버전은 각 문자의 이미지로 학습해야 했으며 한 번에 하나의 글꼴로 작업해야 했다. 대부분 글꼴에 대해 높은 정확도를 생성할 수 있는 이미지 파일 형식 입력을 지원한다. 일부 시스템은 이미지, 열, 기타 비 텍스트 구성요소를 포함해서 원본 페이지에 근접한 형식화된 출력을 재현할 수 있다
정리하면 OCR은 텍스트 이미지를 기계가 읽을 수 있는 문자로 변환하는 과정을 말하는 것이다.
그럼 이 OCR은 어떤 흐름으로 작동하는 것인가?
https://aws.amazon.com/ko/what-is/ocr/
OCR이란 무엇인가요? - 광학 문자 인식 설명 - AWS
대부분 비즈니스 워크플로에는 인쇄 매체에서 정보를 수신하는 과정이 포함됩니다. 종이 양식, 인보이스, 스캔 받은 법률 문서, 인쇄된 계약서는 모두 비즈니스 프로세스에 속합니다. 이러한 대
aws.amazon.com
OCR 엔진 또는 OCR 소프트웨어는 다음 단계로 작동한다.
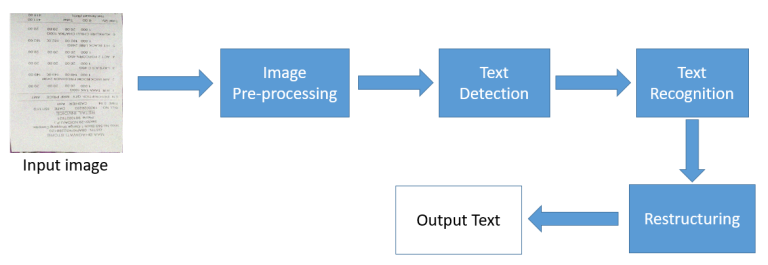
1. 이미지 획득 : 스캐너를 통해 문서를 읽어들여 이진 데이터로 변환한다. OCR 소프트웨어는 스캔된 이미지를 분석하고 밝은 부분을 배경, 어두운 부분을 텍스트로 분류한다
2. 전처리 : OCR 소프트웨어는 먼저 이미지를 정리하고 오류를 제거해서 읽을 수 있게 준비한다. 정리 기술은 아래와 같다
- 스캔된 문서를 조금씩 기울기 보정하거나 틸팅해서 스캔 중의 정렬 문제 해결
- 디지털 이미지의 얼룩을 제거하거나 텍스트 이미지의 가장자리를 부드럽게 만듦
- 이미지 안의 텍스트 상자, 선 정리
- 다국어 OCR 기술용 스크립트 인식
3. 텍스트 인식 : OCR 소프트웨어가 텍스트 인식에 사용하는 OCR 알고리즘 또는 소프트웨어 프로세스의 2가지 주요 유형은 패턴 매칭, 특징 추출이다
- 패턴 매칭 : 글리프라는 문자 이미지를 격리해서 유사하게 저장된 글리프와 비교해서 작동한다. 패턴 인식은 저장된 글리프가 입력된 글리프와 비슷한 폰트, 크기를 가진 경우에만 작동한다. 이 방법은 잘 알려진 폰트로 입력된 문서의 스캔 이미지에서 잘 작동한다
- 특징 추출 : 글리프를 선, 닫힌 고리, 선 방향 및 선 교차와 같은 특징으로 나누거나 분해한다. 그 다음 이런 특징을 써서 다양하게 저장된 글리프 가운데 가장 정확히 일치하거나 근사치에 가까운 글리프를 찾아낸다
4. 후처리 : 분석이 끝나면 시스템은 추출된 테긋트 데이터를 컴퓨터 파일로 변환한다. 일부 OCR 시스템은 문서의 스캔 버전 전, 후를 모두 포함하는 주석이 달린 PDF를 생성할 수 있다
이 과정을 도식화하면 아래와 같다.
그럼 OCR은 왜 사용되는 것인가? 결국은 편리함 때문이다.
대량의 이미지들 속에서 특정 글자를 찾아내야 하는 경우, 그리고 그 글자를 바탕으로 필터링, 정렬 처리를 거쳐서 어떤 데이터를 뽑아내야 하는 경우 OCR은 작업 과정 효율화를 끌어올릴 수 있다.
단순히 생각해 봐도 사진들을 눈 아프게 일일이 확인해 가면서 글자 찾기 놀이하는 것보다, OCR로 텍스트 정리해서 이상한 곁다리들 쳐내고 필터링이든 정렬이든 데이터들을 조작하는 게 좀 더 편할 것 같다.
또한 인공지능 훈련 목적으로도 유용하게 쓰일 것이다. 필체 인식이나 글자들을 컴퓨터가 인식할 수 있게 해서 컴퓨터에게 질문하면 답변을 받을 수 있도록 훈련한다던가 하는 경우가 있다.
이걸 읽고 뭔가 떠오를 것이다. 최근에 뜨거운 감자로 급부상한 ChatGPT다. 그리고 유사품인 Bard와 구글의 인공지능 모델 PaLM을 학습시킬 때 OCR을 아주 유용하게 활용할 수 있다.
그럼 우리 실생활에 OCR은 어떻게 녹아들어 있을까? 몇 가지 예시를 확인한다.
- 유저가 입력만 문장을 읽을 수 있는 챗봇
- 사업자등록증, 신분증 등 문서 인식
- 고지서 인식을 통한 각종 세금 납부
- 차량 번호판 인식을 통한 주정차 단속
- 전자책
이외에도 찾아보면 OCR을 실생활에서 활용하는 사례는 수도 없이 많다. 앞으로 또 어떤 분야에서 OCR이 적용될지 모르는 일이다.