[Android] 초기 데이터 로드 : LaunchedEffect vs ViewModel
이 글은 아래의 미디엄 링크를 번역한 포스팅이다. 2편은 추후 번역한다.
https://medium.com/proandroiddev/loading-initial-data-in-launchedeffect-vs-viewmodel-f1747c20ce62
Loading Initial Data in LaunchedEffect vs. ViewModel
When initializing or fetching data upon entering a screen, it’s crucial to select the right trigger point for loading the initial data…
proandroiddev.com
화면에 들어갔을 때 데이터를 초기화하거나 가져올 경우 초기 데이터를 불러오기 위한 올바른 트리거 포인트를 선택하는 게 중요하다. 대부분의 데이터 Flow가 제공자, 구독자에 의해 제공되므로 적절한 데이터 생명주기 관리는 필수적이다.
특히 컴포즈에서 컴포저블 함수의 생명주기는 액티비티와 많이 다르다. 또한 컴포즈의 네비게이션 라이브러리를 쓸 때 각 화면에는 고유 생명주기가 있으므로 데이터 생명주기는 요구사항에 따라 각 화면의 특정 수명에 맞춰야 한다.
여기선 최근 Dove Letter에서 제기된 주제인 컴포저블 함수 및 뷰모델 안에서 초기 데이터를 로드할 위치에 대한 토론을 살펴본다.
LaunchedEffect vs ViewModel.init 중 어디서 초기 데이터를 불러와야 하는가?
가장 일반적으로 논의되는 접근방식 하나는 초기 데이터 로드를 컴포저블의 LaunchedEffect, 뷰모델의 init에서 로드할지 여부다. 공식 안드로이드 문서를 보면 문서와 아키텍처 샘플 깃허브에서 볼 수 있듯 뷰모델의 init 안에서 데이터를 로드하는 걸 권장하는 경우가 많다.
커뮤니티에서 일반적으로 초기 데이터를 불러오는 방법을 설문조사한 결과는 아래와 같다.
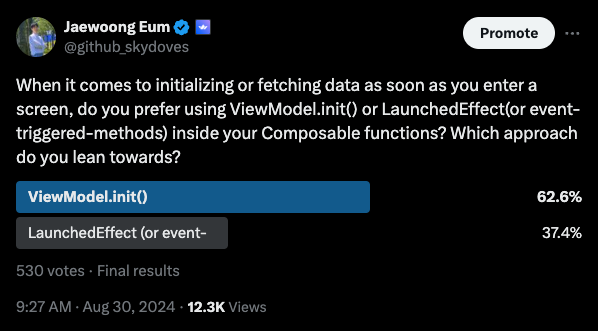
대다수가 뷰모델에서 초기 데이터를 로드하는 걸 선호한다. 아래는 커뮤니티의 누군가가 뷰모델의 init이 더 나은 선택인 이유다.

UI 레이어는 주로 시각적 표현이므로 데이터 초기화 관리를 위해 LaunchedEffect에 의존하기보다 관심사를 분리하는 게 중요하단 점에서 이 관점은 설득력 있다. 반면 이 커뮤니티 구독자들은 함수 호출의 유연성, 단위 테스트의 용이성 면에서 LaunchedEffect가 더 나은 옵션이 될 수 있다고 강조한다.

LaunchedEffect가 제공하는 유연성, 단위 테스트 용이성을 강조해서 이 관점도 설득력 있다. 이벤트 트리거 기반 초기화에 의존하면 추가 책임 없이 뷰모델이 원래 목적에 집중할 수 있다. 이로 인해 초기 데이터를 불러오는 모범 사례는 뭔가라는 일반 딜레마에 직면한다.
둘 다 안티 패턴이다 : Lazy Observation 사용
두 방식 모두 단점이 있다. 구글 안드로이드 툴킷 팀의 이안 레이크는 실제론 두 방식 모두 안티 패턴으로 간주한다고 언급했다.
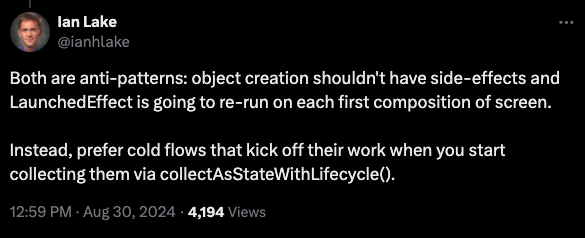
뷰모델 init에서 초기 데이터를 불러오면 뷰모델을 만드는 동안 사이드 이펙트가 발생해서 기본 목적에서 벗어나고 생명주기 관리가 복잡해질 수 있다. 반면 LaunchedEffect에서 데이터를 초기화하면 화면을 처음 구성할 때마다 다시 트리거될 위험이 있다.
컴포저블 함수의 생명주기가 뷰모델 생명주기와 다르면 의도하지 않은 동작이 발생하고 예상했던 데이터 Flow가 중단될 수 있다. 그럼 초기화의 모범 사례는 무엇인가?
이안 레이크는 지연 초기화를 위해 Cold Flow를 사용할 걸 권장한다. 또는 StateFlow, SharedFlow 같은 Hot Flow를 활용할 수 있는데 이 Flow는 Flow를 stateIn(), shareIn()과 결합해서 생성하고 시작 매개변수로 SharingStarted.WhileSubscribed를 써서 Flow 생명주기를 효율적으로 관리할 수 있다. 이걸 쓰면 구성 변경 시 초기 데이터가 유지되므로 상태를 더 안정적으로 관리할 수 있다. 또한 컴포즈에서 collectAsStateWithLifecycle을 써서 이런 Flow를 구독해야 한다.
이 접근법을 사용하면 공유가 시작되는 시기를 제어하고, UI 계층에서 구독이 발생할 때 데이터를 느리게 가져오게 할 수 있다.
지연 관찰 모범 사례
이 접근법의 예는 Pokedex-Compose 프로젝트에서 찾을 수 있다.
https://github.com/skydoves/pokedex-compose
GitHub - skydoves/pokedex-compose: 🗡️ Pokedex Compose demonstrates modern Android development with Jetpack Compose, Hilt, C
🗡️ Pokedex Compose demonstrates modern Android development with Jetpack Compose, Hilt, Coroutines, Flow, Jetpack (Room, ViewModel), and Material Design based on MVVM architecture. - skydoves/pokede...
github.com
val pokemon = savedStateHandle.getStateFlow<Pokemon?>("pokemon", null)
val pokemonInfo: StateFlow<PokemonInfo?> =
pokemon.filterNotNull().flatMapLatest { pokemon ->
detailsRepository.fetchPokemonInfo(
..
)
}.stateIn(
scope = viewModelScope,
started = SharingStarted.WhileSubscribed(5_000),
initialValue = null,
)
위 예에선 stateIn()과 SharingStarted.WhileSubscribed()를 합쳐서 Hot Flow(StateFlow)를 만들었다. 이렇게 하면 첫 구독자가 나타날 때 공유가 시작되고 지정한 stopTimeoutMillis 매개변수에 따라 마지막 구독자가 사라지면 즉시 중지된다.
결과적으로 Hot Flow는 UI 계층에서 첫 구독자가 나타나자마자 값을 방출하기 시작해서 UI에서 실제로 필요할 때만 초기 데이터가 불러와지는 걸 보장한다. 이 접근법은 필요하지 않을 때 불필요한 데이터 가져오기를 방지하고, 마지막 구독자가 사라지면 값 방출을 중지한다.
그런데 5_000은 어디서 온 숫자인가?
5_000이란 값이 매개변수로 선택된 배경은 안드로이드 공식 문서 중 ANR 문서에서 찾을 수 있다.
https://developer.android.com/topic/performance/vitals/anr?hl=ko
ANR | App quality | Android Developers
이 페이지는 Cloud Translation API를 통해 번역되었습니다. ANR 컬렉션을 사용해 정리하기 내 환경설정을 기준으로 콘텐츠를 저장하고 분류하세요. Android 앱의 UI 스레드가 너무 오랫동안 차단되면 'ANR
developer.android.com
여기선 ANR 시간 초과 임계값을 설명하고 있다. UI 쓰레드가 너무 오래 차단되면 ANR 오류가 트리거된다고 설명한다. 구체적으로 앱이 키 누르기, 화면 터치 같은 입력 이벤트에 5초 안에 응답하지 않으면 ANR이 트리거된다. 따라서 마지막 구독자가 5초 이상 사라지면 이미 타임아웃을 초과한 것이며, 데이터 Flow가 더 이상 UI 계층에 영향을 줄 수 없단 뜻이다.
이 시점에서 UI를 더 이상 렌더링할 필요가 없거나 이미 ANR이 발생했을 수 있다. 하지만 정확한 5_000 타임아웃으로 같은 stateIn 보일러 플레이트 코드를 반복 작성하는 게 번거로우면 아래처럼 Context 리시버를 써서 확장 함수를 만들어 코드를 간소화할 수 있다.
context(ViewModel)
fun <T> Flow<T>.stateInWhileSubscribed(initialValue: T): StateFlow<T> {
return stateIn(
scope = viewModelScope,
started = SharingStarted.WhileSubscribed(5_000),
initialValue = initialValue,
)
}
또한 아래 답변에서 볼 수 있듯이 이안 레이크가 5_000 타임아웃은 ANR 기한과 정확히 일치한다고 언급했다.

collectAsStateWithLifecycle vs collectAsState
다른 중요 주제는 생명주기 관리다. LiveData를 쓸 때 옵저버는 안드로이드 생명주기와 긴밀하게 통합되므로 구독 취소가 자동으로 이뤄진다. 그러나 Flow에선 적절한 구독 취소를 위해 생명주기 관리를 수동으로 처리해야 한다. collectAsState와 달리 collectAsStateWithLifecycle을 쓰면 앱이 백그라운드에 있을 때와 같이 안드로이드 생명주기에 따라 필요하지 않은 경우 리소스를 절약할 수 있다. 리소스를 활성 상태로 불필요하게 유지하면 기기 성능, 배터리에 영향을 줄 수 있어서 collectAsStateWithLifecycle은 collectAsState의 생명주기 인식 버전이다. 이 함수를 잘 보면 생명주기 시스템에 따라 안드로이드 Flow를 안전하게 소비하는 권장 방법인 repeatOnLifecycle API를 사용하는 걸 볼 수 있다.
/**
* Collects values from this [Flow] and represents its latest value via [State] in a lifecycle-aware
* manner.
*
* Every time there would be new value posted into the [Flow] the returned [State] will be updated
* causing recomposition of every [State.value] usage whenever the [lifecycle] is at least
* [minActiveState].
*
* This [Flow] is collected every time [lifecycle] reaches the [minActiveState] Lifecycle state. The
* collection stops when [lifecycle] falls below [minActiveState].
*/
@Composable
fun <T> Flow<T>.collectAsStateWithLifecycle(
initialValue: T,
lifecycle: Lifecycle,
minActiveState: Lifecycle.State = Lifecycle.State.STARTED,
context: CoroutineContext = EmptyCoroutineContext
): State<T> {
return produceState(initialValue, this, lifecycle, minActiveState, context) {
lifecycle.repeatOnLifecycle(minActiveState) {
if (context == EmptyCoroutineContext) {
this@collectAsStateWithLifecycle.collect { this@produceState.value = it }
} else
withContext(context) {
this@collectAsStateWithLifecycle.collect { this@produceState.value = it }
}
}
}
}
collectAsStateWithLifecycle을 쓰면 안드로이드 생명주기에 맞춰 Flow를 관찰할 수 있다. 생명주기가 지정된 최소 활성 상태(기본값 onStart)에 도달하면 collect를 시작하고 onStop에 도달하면 collect를 중지한다.
즉 앱이 더 이상 화면에 표시되지 않거나 폐기될 때 앱 리소스를 확보하기 위해 Flow collect가 중지된다. 따라서 더 이상 필요하지 않을 때 데이터 계층 리소스를 안전하게 해제해서 리소스 사용을 최적화할 수 있다.
결론
기존 XML에서 컴포즈로, LiveData에서 Flow로 전환하면서 방법은 진화했지만 핵심 과제인 문제 해결은 여전히 동일하다. 모든 문제를 해결할 수 있는 만능 솔루션은 없다. 프로젝트마다 고유한 요구사항이 있으므로 이런 요구사항을 이해하는 게 가장 적합한 접근 방식을 선택하는 데 중요하다.